내 손 안에 초지능
AI가 전문성을 압축해줄 때, 끝내 인간에게 남는 것
2026년 4월 15일
내 손 안에 초지능
AI가 전문성을 압축해줄 때, 끝내 인간에게 남는 것
나는 8년차 프론트엔드 개발자다. 그동안 수 없이 많은 Vue, React와 TypeScript 코드를 작성했다. 컴파일러 이론을 전공한 적 없고, 박사는 커녕 석사 학위도 없다.
그리고 4개월 전부터, 나는 AI 에이전트를 위한 상태 기술 언어의 DSL 컴파일러를 설계하고 있었다. 형식 의미론, 타입 시스템 건전성, 중간 표현 설계 — 전부 내 전문 분야가 아닌 것들이었다. 그리고 2026년 4월, 이 프레임워크 위에서 수행한 실험을 arXiv에 올렸다.
나는 이 모든 것을 AI와 함께 했다. AI 없이는 불가능했을 것이다. 놀라운 동시에 두렵다. 사람이 수년간 학습하고 경험해야 도달할 수 있는 경지의 상당 부분을, 나는 4개월 만에 따라잡은 느낌이다. 내 체감으로는 80% 정도. 그리고 바로 그 “80%“라는 숫자가, 경이로우면서도 불안하다.
이름 없는 감각
이야기는 AI보다 훨씬 전에 시작됐다.
나는 지난 수년간 다양한 SaaS를 만들었다. IoT 관제 시스템, 지도 기반 도구, 그 밖에 여러 도메인의 제품들. 매번 새로운 비즈니스 로직을 구현하면서, 이상한 감각이 쌓였다. 도메인이 달라도 같은 구조가 반복된다.
이커머스의 “장바구니 → 결제 → 배송”과 로보틱스의 “임무 할당 → 실행 → 보고”. 표면은 완전히 다른데, 상태가 전이되는 방식, 조건이 분기하는 패턴, 예외가 처리되는 구조가 놀라울 정도로 닮아 있었다. 단순한 디자인 패턴의 반복이 아니었다. 더 깊은 층위에서, 도메인 자체가 공유하는 의미론적 뼈대가 있다는 느낌.
이 직감에는 이름이 없었다. 그래서 한동안 그냥 묻어뒀다. 그러다 어느 날 달리기 중에, 그 직감은 하나의 문장으로 수렴했다.
하나의 공리
나에게는 하루 5km를 달리는 습관이 있다. 월 140km, 거의 4년째. 달리는 동안의 사고는 선형적이지 않다 — 개념에서 개념으로 하이퍼링크처럼 점프한다. 이런 비선형적인 사고방식은, 기존 해법의 빈자리를 감지하는 데는 쓸모가 있다.
수년간 쌓인 직감이, 우레탄 위에서 한 문장이 됐다.
모든 도메인은 하나의 의미론적 공간 위의 좌표다.
물류든 핀테크든 헬스케어든, 각 도메인은 고유한 세계처럼 보이지만, 실은 하나의 더 큰 의미론적 공간에서 서로 다른 좌표를 점유하고 있을 뿐이다. 그 공간의 축은 상태, 전이, 제약이라는 보편적 구성요소다.
이 짧은 문장이 Manifesto 프로젝트의 출발점이었다. 이 이론을 받아들이면 자연스럽게 따라오는 것들이 있다. 도메인의 구조를 형식적으로 기술할 언어가 필요하다. 그 언어 위에서 AI가 추론하려면 결정론적이어야 한다. 사람과 AI가 같은 세계 모델을 공유하려면, 양쪽 모두에게 읽히는 의미론적 인터페이스여야 한다.
이론은 있었다. 문제는, 그것을 실제 시스템으로 만들 능력이 내게 없다는 것이었다.
손을 뻗을 수 없던 곳에 손을 뻗다
4개월 전까지의 나는 프론트엔드 개발자였다. 지금의 나는 — 여전히 프론트엔드 개발자지만 — DSL 컴파일러를 설계하고, 형식 언어를 정의하고, arXiv에 논문을 올린 사람이기도 하다.
이게 어떻게 가능했는가? 솔직하게 답하겠다.
이론을 시스템으로 구체화하려면, 나는 최소한 세 개의 전문 영역에 발을 들여야 했다. 형식 언어 이론, 컴파일러 설계, 그리고 대규모 프레임워크 개발 참여 경험. 전부 내 커리어와 무관한 분야들이다. 정상적인 경로라면 각각 수년의 학습이 필요하다.
그래서 나는 AI를 썼다. 코딩 보조가 아니라, 각 분야 전문가의 사고방식을 빌리는 도구로.
결과적으로 만들어진 것이 MEL(Manifesto Expression Language)이라는 상태 기술 언어와 그 런타임인 Manifesto Core다. 도메인의 상태 전이를 비순환 방향 그래프(DAG)로 모델링하며, 의도적으로 튜링 완전하지 않다. 표현력을 제한하는 대신, 상태 공간을 완전히 열거할 수 있고, 데드락을 실행 전에 감지할 수 있다. AI 에이전트에게 “이 행동을 하면 무슨 일이 일어나는가”에 대해 항상 결정론적인 답이 존재하는 세계를 제공하는 것이다.
에이전트 상태와 confidence signal, guarded action, 가상 전이 같은 판단 구조가 런타임 바깥으로 외부화되어, 내부 상태를 항상 들여다볼 수 있게 된다. 블랙박스가 아니라, 열어볼 수 있는 상자.
말로만 설명하면 와닿지 않을 수 있으니, 실제 MEL 코드를 보여주겠다. 가장 단순한 예시로, 스코어보드 도메인이다:
domain Score {
state {
home: number = 0
away: number = 0
}
computed total = add(home, away)
computed isHomeLeading = gt(home, away)
computed isDraw = eq(home, away)
action homeScore() {
onceIntent {
patch home = add(home, 1)
}
}
}state는 변할 수 있는 값, computed는 상태에서 자동으로 파생되는 값, action은 상태를 변경하는 유일한 경로다. 이것이 컴파일되면, 런타임은 아래와 같은 의존성 그래프를 자동으로 생성한다.
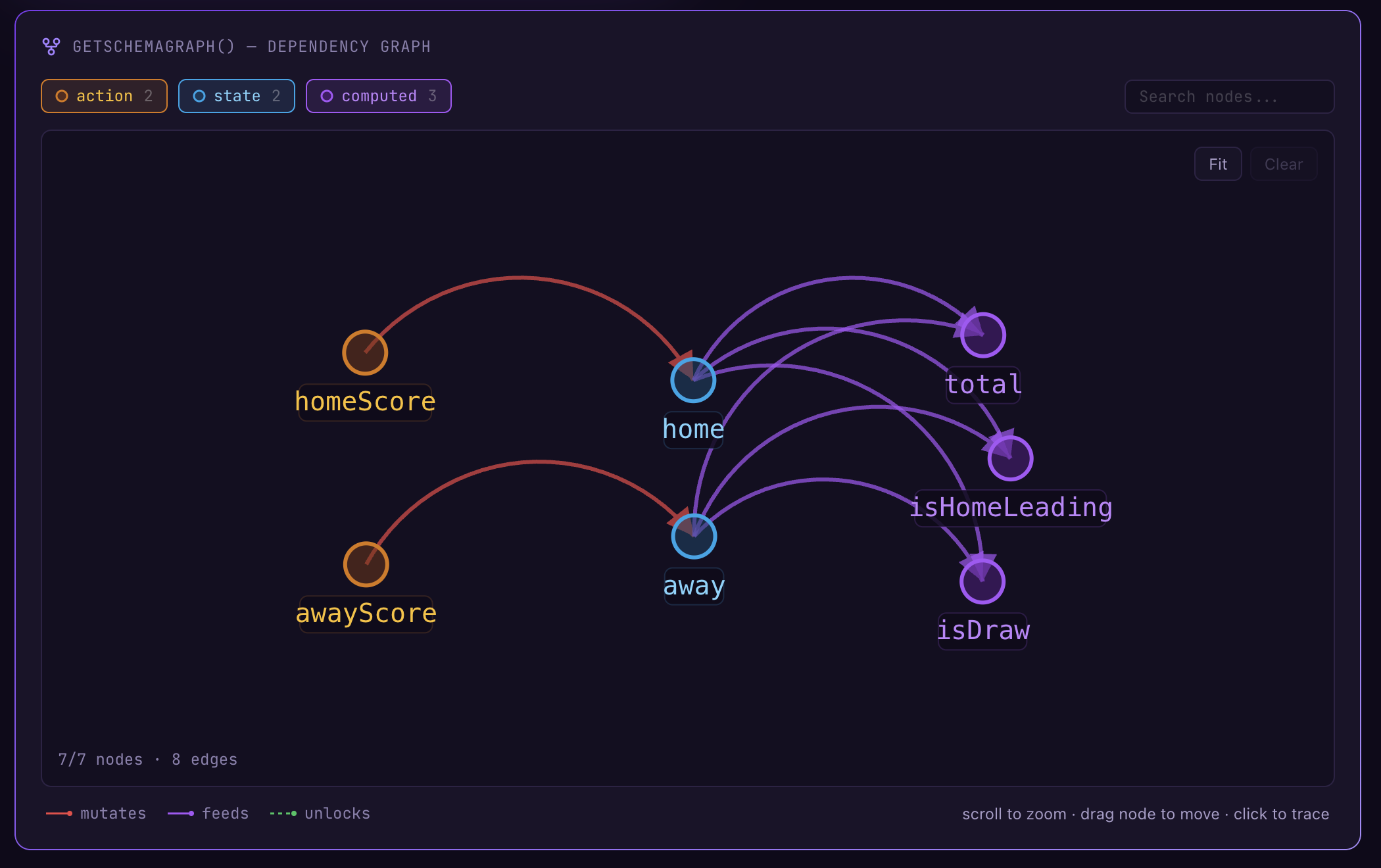
이 그래프가 비순환(acyclic)이기 때문에 어떤 action을 실행해도 시스템이 어떤 상태에 도달하는지 사전에 완전히 예측할 수 있다. AI 에이전트는 이 그래프를 읽고, “homeScore()를 실행하면 total이 올라가고 isDraw가 false가 된다”는 것을 추론이 아닌 계산으로 알 수 있다.
컴파일러 전문가가 이걸 보면 어떻게 평가할지 모르겠다. 형식 언어 연구자가 보면 허점을 찾아낼 수도 있다. 하지만 적어도 이것은 작동한다. 스트레스 테스트를 통과했고, 그 위에서 실제로 실험을 돌릴 수 있었다.
다만, 여기까지 오는 길이 순탄했던 건 아니다. 거의 완성한 v1의 아키텍처에서 내부 기능 간의 모순을 발견하고, 제로 베이스부터 다시 구현한 것이 네 번이었다. 보통이라면 치명적인 일정 지연이다. 하지만 Codex와 Claude Code를 쓰면서, 전체 재구현이 이틀 안에 끝났다. 그래서 두렵지 않았다 — “이 설계가 틀렸다”는 판단이 들면, 버리고 다시 짜면 됐다. AI가 바꿔준 건 능력만이 아니다. 실패의 비용을 바꿔줬다.
AI는 어떻게 “80%“를 만들어주는가
나는 여러 AI를 역할별로 썼다. 어떤 모델은 스펙의 모순을 집요하게 찔렀고, 어떤 모델은 아키텍처의 장기적 일관성을 봤고, 어떤 모델은 형태가 잡히지 않은 아이디어의 탐색 폭을 넓혀줬다.
중요한 건 모델 이름이 아니었다. 내가 매일 여러 분야 전문가와 짧은 피드백 루프를 돌리는 것과 비슷한 환경을 갖게 됐다는 점이었다. 완벽하지는 않지만, 방향이 맞는지 틀렸는지를 빠르게 가를 만큼은 충분했다.
그리고 이 빠른 피드백 루프는 실패의 비용을 구조적으로 낮춰줬다. 잘못된 방향으로 이틀을 걸어도, 되돌아오는 데는 반나절이면 충분했다. 그래서 시도 자체를 두려워할 이유가 없었다. 타입 시스템을 처음부터 다시 설계하는 것도, 익숙하지 않은 형식 의미론에 도전하는 것도, “틀리면 돌아오면 된다”는 감각 위에서 가능했다. 실패가 싸지면 탐색 범위가 넓어진다. 탐색 범위가 넓어지면, 비전문가도 전문가의 영역 근처까지 걸어갈 수 있다.
이것이 내가 말하는 “80%“의 실체다. AI는 수년간 한 분야를 파고든 사람의 판단력을 완전히 대체하지는 못한다. 하지만 비전문가인 내가 전문가의 영역에서 의미 있는 결과물을 만들 수 있을 정도까지는 끌어올려준다.
나머지 20%는 무엇인가?
나머지 20%, 그리고 AI에게 맡기면 안 되는 것
프레임워크 설계 초기에, MEL의 핵심 추상화 레벨을 정하는 문제를 AI에게 물었다. “상태 전이를 얼마나 세분화해야 하는가?” AI는 3계층 구조를 제안했고, 논리적으로 완벽해 보였다. 나는 그대로 구현했다.
2주 뒤, 실제 도메인을 모델링하면서 그 구조가 근본적으로 맞지 않는다는 걸 깨달았다. 예를 들어, IoT 디바이스 관제에서 “센서가 펌웨어 업데이트 중일 때 이상 징후 알림이 들어오는” 상황은 AI가 제안한 계층 구조에서 두 레이어를 동시에 관통했다. 계층 간 경계가 깔끔한 이론적 분류에는 맞았지만, 현실의 도메인은 그 경계를 존중하지 않았다. 결국 계층을 버리고 평탄한 상태-전이 그래프로 재설계해야 했다. AI는 내가 제시한 제약 조건 안에서 최적의 답을 줬지만, 제약 조건 자체가 틀렸다. 잘못된 질문에 대한 완벽한 답.
이것이 나머지 20%의 정체다. 어떤 추상화가 올바른지, 어떤 문제가 진짜 문제인지, 어떤 트레이드오프를 감수할 것인지 — 이 판단들은 AI가 대신해줄 수 없다. AI는 내가 던진 질문의 범위 안에서만 움직인다. 질문 자체를 교정하는 것, “내가 지금 잘못된 걸 묻고 있다”는 감각은 여전히 인간의 몫이다.
그리고 이 20%가 바로, 우리가 “전문가”라고 부르는 사람들이 가진 직관의 정체다. 수천 번의 실패에서 체득한 감각, 분야 전체를 조망하는 시야, “이건 아닌데”라는 말로 설명할 수 없는 판단력. 그것은 평생의 학습 과정에서만 쌓이는 것이다. AI가 압축해준 것은 형식화와 구현의 기술이지, 그런 종류의 직관이 아니다.
체감 80%라는 감각은 경이롭지만, 동시에 위험하다. “거의 다 된 것”처럼 느껴지기 때문이다. 하지만 그 나머지가 없으면 — 자기가 뭘 모르는지조차 모르는 상태에서 — 형식적으로 완벽해 보이지만 본질적으로 공허한 것을 만들 수 있다.
솔직히 말하면, 나는 내가 그 나머지를 채웠는지 모른다. 아마 못 채웠을 것이다. AI가 도와준 영역에서는 자신감이 있지만, 내가 보지 못하는 맹점이 어디에 있는지는 나 자신이 판단할 수 없다 — 그게 맹점의 정의니까.
그래서 논문을 쓰기로 했다. 방 안에서 혼자 “이게 맞나?”를 되뇌는 것으로는 답이 나오지 않았다. 내가 만든 것이 의미 있는 기여인지, 아니면 그럴듯하게 포장된 착각인지, 그 판단은 실제로 20%를 가진 전문가들에게 맡겨야 했다. arXiv에 올린 것은, 그 평가를 피하지 않겠다는 선택이었다.
논문을 쓴다는 것
프레임워크를 만든 것과 논문으로 쓰는 것은 전혀 다른 차원의 도전이었다. 하지만 논문은 단순히 성과를 알리기 위한 것이 아니었다. 내가 만든 것을 가장 엄격한 형식으로 정리하고, 전문가들 앞에 내밀어서, “이게 진짜 의미 있는 겁니까?”라고 물어보는 과정이었다.
연구의 세계에는 암묵적인 문법이 있다. 동기를 어떻게 구성하는지, 실험 설계에서 무엇을 보여야 하는지, 결과를 어떤 톤으로 서술하는지. 코드를 아무리 잘 짜도 알 수 없는 것들이다. 나는 이 문법을 배운 적이 없었다.
그런데 AI가 이 과정마저 압축해줬다.
관련 연구(related work) 서베이가 대표적이다. 학술 연구에서 관련 연구를 파악하는 건 가장 시간이 많이 드는 과정 중 하나다. 나는 AI에게 프로젝트를 설명하고 “이것과 비슷한 연구를 찾아봐”라고 했다. 그러자 선언형 런타임, 에이전트 아키텍처, 세계 모델 기반 계획의 핵심 논문들이 빠르게 정리됐고, 내 연구가 그 계보 어디에 놓이는지도 훨씬 빨리 보이기 시작했다. 몇 달 걸릴 수 있는 탐색이 하루 만에 압축됐다.
학술적 영어의 뉘앙스도 마찬가지였다. “We propose”와 “We introduce”의 미묘한 차이, 실험 결과를 과장하지 않으면서도 의미를 전달하는 서술법, 한계점을 솔직하게 인정하면서도 기여를 훼손하지 않는 균형 — 이런 것들을 AI가 실시간으로 교정해줬다.
최종적으로 arXiv에 올린 논문의 제목은 “How Much LLM Does a Self-Revising Agent Actually Need?” 이다. 내가 묻고 싶었던 것은 성능 그 자체가 아니었다. Manifesto Core처럼 추론 과정을 열어볼 수 있는 런타임 위에서, LLM이 실제로 필요한 순간과 룰 기반 추론이 더 나은 순간을 분리해 측정할 수 있는가. 선언형 런타임 위에서 에이전트의 능력을 4단계로 점진적으로 분해해 실험했다.
초기 결과는 흥미로웠다. 노이즈가 있는 협력적 배틀쉽 벤치마크에서 54게임(18보드 × 3시드)을 돌렸을 때, 명시적 세계 모델 계획(world-model planning)만 추가해도 승률이 24.1%p 상승했다. 반면 LLM 기반 수정은 전체 턴의 약 4.3%에서만 호출됐고, 오히려 승률을 떨어뜨렸다. 내게 이 논문의 핵심은 리더보드 성능이 아니다. reflection을 선언형 런타임으로 외부화하면, LLM의 기여 지점과 비기여 지점을 실증적으로 분해해 볼 수 있다는 데 있다.
이 논문이 받아들여질지는 모른다. 하지만 적어도, 내가 물어보고 싶었던 질문을 물어볼 수 있었다. 그것만으로도 4개월 전에는 상상할 수 없던 곳에 서 있다.
arXiv에 프리프린트를 올린 날, 성취감과 불안이 동시에 밀려왔다. arXiv는 관문이 아니라 출발선이다. 내 논문이 의미 있는 기여인지, 내가 보지 못한 맹점이 치명적인 것인지는, 그 20%를 가진 사람들이 판단해줄 것이다. 나는 그 판단을 피하지 않을 것이다 — 애초에 그 판단을 받기 위해 쓴 논문이니까.
초지능은 어디에 있는가
이 글의 제목은 의도적으로 도발적이다. 사실 “초지능”은 아직 존재하는지는 잘 모르겠다.
하지만 내 손 안에 있는 도구는, 내가 평생 닿을 수 없다고 생각했던 분야의 문을 열어줬다. 그것도 한 분야가 아니라 여러 분야를 동시에. 이전에는 “나는 프론트엔드 개발자니까”라는 경계가 있었다. AI는 그 경계를 허문 게 아니라, 경계 너머를 탐색할 수 있는 최소한의 장비를 줬다.
이 경험들은 경이롭다. 그리고 솔직히 두렵다.
경이로운 이유는 명확하다. 한 사람이 접근할 수 있는 지적 영역의 범위가 전례 없이 넓어졌다. 두려운 이유도 명확하다. “거의 다 왔다”는 체감이 너무 쉽게 찾아오면, 자기가 도달하지 못한 나머지의 중요성을 잊기 쉽다. 그리고 그 나머지를 모른 채 만든 것들이 세상에 나가면, 그럴듯한 허상이 진짜 전문성을 대체하는 세계가 올 수 있다.
나는 그런 세계를 원하지 않는다. 하지만 동시에, AI가 열어준 가능성을 포기하고 싶지도 않다. 이 긴장 위에서 균형을 잡는 것이, 지금 AI를 쓰는 모든 사람의 과제라고 생각한다.
에필로그: 화면을 끄고
오늘 아침에도 달렸다. 달리는 동안 이 글을 머릿속에서 구성했다. AI에게 초안을 맡기기 전에, 내가 무슨 이야기를 하고 싶은지 먼저 정리했다.
수년간 SaaS를 만들며 느꼈던 이름 없는 감각 — 도메인들이 공유하는 보이지 않는 구조에 대한 직감. 그것은 어떤 프롬프트로도 생성할 수 없는 것이었다. AI는 그 직감을 형식으로 번역해줬을 뿐이다.
그런데 한 가지 질문이 달리는 내내 떠나지 않았다.
내가 AI로 4개월 만에 도달했다고 느끼는 이 자리에, 10년을 투자한 전문가가 서 있다. 지금 이 순간, 그 전문가의 손에도 같은 AI가 들려 있다. 그 사람은 지금 어디까지 가고 있는가?
나는 AI 덕분에 경계를 넘었다고 생각했다. 하지만 어쩌면 경계는 허물어진 게 아니라, 모든 사람에게 동시에 확장된 것인지도 모른다. 내가 전문가의 영역에 발을 들이는 동안, 이미 그 안에 있던 사람들은 더 멀리 가고 있을 수 있다.
그 생각이 들었을 때, 화면을 끄고 더 빨리 달렸다.