Superintelligence in My Hands
What remains irreducibly human when AI compresses expertise
April 15, 2026
This essay was originally written in Korean and translated into English with the help of AI.
Superintelligence in My Hands
What remains irreducibly human when AI compresses expertise
I’m a frontend developer in my eighth year. I’ve written countless lines of Vue, React, and TypeScript. No background in compiler theory. No master’s degree, let alone a PhD.
Starting four months ago, I was designing a DSL (domain-specific language) compiler for a state description language built for AI agents. Formal semantics, type system soundness, intermediate representation design — none of it was my field. In April 2026, I put an experiment built on this framework on arXiv.
I did all of this with AI. It would have been impossible without it. And that fact is both exhilarating and frightening. It feels like I’ve caught up to roughly 80% of what would normally take years of dedicated study and experience — in four months. That “80%” is the number that keeps me up at night.
A feeling with no name
The story starts long before AI.
Over the past several years, I’ve built a variety of SaaS products. IoT fleet management, map-based tools, products across different domains. With each new business logic I implemented, a strange feeling accumulated: different domains kept exhibiting the same structures.
E-commerce’s “cart → checkout → shipping” and robotics’ “mission assignment → execution → report.” The surface couldn’t be more different, but the way states transitioned, conditions branched, and exceptions were handled — these were strikingly similar. It wasn’t just design patterns repeating. Deeper down, the domains themselves seemed to share a semantic skeleton.
I had no name for this intuition. So I shelved it. Then one day, on a run, it collapsed into a single sentence.
One axiom
I run 5km a day. About 140km a month, going on four years now. My thinking during runs isn’t linear — it jumps from concept to concept like hyperlinks. That kind of nonlinear thinking is useful for detecting gaps in existing solutions.
Years of accumulated intuition crystallized on the track into one sentence:
Every domain is a coordinate in a single semantic space.
Logistics, fintech, healthcare — each domain looks like its own world, but they’re really just occupying different coordinates in a larger semantic space. The axes of that space are universal primitives: state, transition, and constraint.
This short sentence was the starting point of Manifesto. Once you accept this thesis, certain things follow naturally. You need a language that can formally describe domain structures. For AI to reason over that language, it must be deterministic. For humans and AI to share the same world model, it must be a semantic interface readable by both.
I had the thesis. What I didn’t have was the ability to turn it into a real system.
Reaching where I couldn’t reach
Until four months ago, I was a frontend developer. Now I’m still a frontend developer — but also someone who designed a DSL compiler, defined a formal language, and put a paper on arXiv.
How was this possible? Let me be honest.
To turn the thesis into a system, I needed to step into at least three expert domains: formal language theory, compiler design, and hands-on experience building large-scale frameworks. All completely unrelated to my career. Under normal circumstances, each would require years of study.
So I used AI. Not as a coding assistant, but as a way to borrow expert thinking patterns from each field.
The result was MEL (Manifesto Expression Language) — a state description language and its runtime, Manifesto Core. It models domain state transitions as a directed acyclic graph (DAG) and is intentionally not Turing-complete. By restricting expressiveness, the system gains the ability to fully enumerate the state space and detect deadlocks before execution. It gives AI agents a world where “what happens if I take this action?” always has a deterministic answer.
Agent state, confidence signals, guarded actions, and hypothetical transitions are externalized as runtime structures, so the agent’s internal state remains inspectable. Not a black box — a box you can open.
Words only go so far, so here’s actual MEL code. The simplest example — a scoreboard domain:
domain Score {
state {
home: number = 0
away: number = 0
}
computed total = add(home, away)
computed isHomeLeading = gt(home, away)
computed isDraw = eq(home, away)
action homeScore() {
onceIntent {
patch home = add(home, 1)
}
}
}state holds mutable values, computed are values derived automatically from state, and action is the only pathway to mutate state. When compiled, the runtime automatically generates a dependency graph like this:
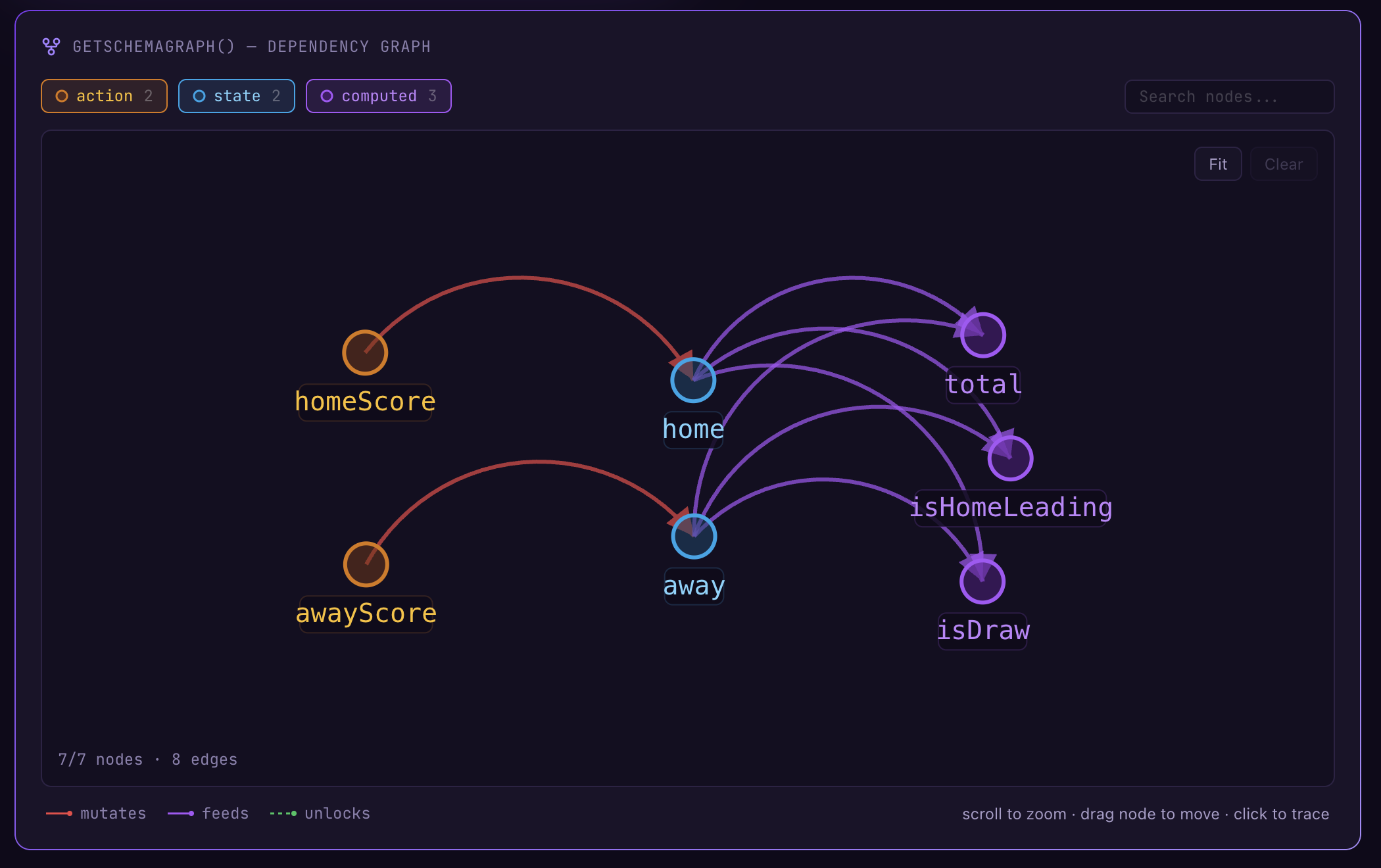
Because this graph is acyclic, the outcome of any action is fully predictable before execution. An AI agent can read this graph and know — by computation, not inference — that calling homeScore() will increment total and set isDraw to false.
Would a compiler expert find holes in this? Probably. Would a formal language researcher have designed it differently? Almost certainly. But it works. It passed stress testing, and I was able to run real experiments on it.
Getting here wasn’t smooth, though. Four times, I discovered contradictions between internal features in a nearly-finished v1 architecture and rewrote the entire thing from zero. Normally, that would be a catastrophic schedule hit. But with Codex and Claude Code, a full reimplementation took less than two days. So it wasn’t scary — when the judgment “this design is wrong” hit, I could throw it away and rebuild. AI didn’t just change my capabilities. It changed the cost of failure.
How AI gets you to “80%”
I used multiple AIs in different roles. Some were relentless at finding contradictions in specs. Some were better at long-horizon architectural judgment. Some were better at widening the possibility space before an idea had fully taken shape.
The important part wasn’t the model names. It was that I could run something like a daily feedback loop with several expert perspectives at once. Not perfectly, but well enough to tell whether a direction was sound or broken.
And this fast feedback loop structurally lowered the cost of failure. Even if I walked two days in the wrong direction, half a day was enough to walk back. So there was no reason to fear the attempt itself. Redesigning the type system from scratch, venturing into unfamiliar formal semantics — all of it was possible on the foundation of “if it’s wrong, just come back.” When failure is cheap, the range of exploration widens. When the range of exploration widens, even a non-expert can walk close to expert territory.
That’s what I mean by “80%.” AI doesn’t replace the judgment of someone who has spent years in a field. But it can lift a non-expert far enough to produce meaningful work inside expert territory.
So what’s the remaining 20%?
The remaining 20%, and what you should never delegate to AI
Early in the framework design, I asked AI to decide MEL’s core abstraction level. “How granular should state transitions be?” It proposed a three-tier architecture that looked logically flawless. I implemented it.
Two weeks later, modeling a real domain, I realized the structure was fundamentally wrong. In an IoT fleet management scenario, a case like “a sensor receives an anomaly alert while mid-firmware-update” cut across two of the proposed tiers simultaneously. The tier boundaries were clean in theory, but real domains don’t respect theoretical boundaries. I had to scrap the hierarchy and redesign around a flat state-transition graph. AI gave the optimal answer within the constraints I set — but the constraints themselves were wrong. A perfect answer to a wrong question.
This is what the remaining 20% is. Which abstraction is right, which problem is the real problem, which trade-offs to accept — these judgments can’t be delegated to AI. AI only moves within the scope of the question you throw at it. Correcting the question itself — the gut feeling that “I’m asking the wrong thing right now” — is still a human job.
And this 20% is exactly what we mean when we call someone an “expert.” The instinct forged through thousands of failures, the ability to survey an entire field, the judgment that can’t be explained beyond “this doesn’t feel right.” That’s built through a lifetime of learning. What AI compressed for me was the skill of formalization and implementation — not that kind of intuition.
That felt 80% is remarkable, but it’s also dangerous. It creates the illusion of “almost there.” But without the rest — in a state where you don’t know what you don’t know — you can build things that look formally perfect but are fundamentally hollow.
To be honest, I don’t know whether I’ve filled that remaining gap. I probably haven’t. I’m confident in the ground AI helped me reach, but I can’t judge where my own blind spots are — that’s what makes them blind spots.
That’s why I decided to write a paper. Sitting alone asking myself “is this right?” wasn’t getting me anywhere. Whether what I built is a meaningful contribution or a well-packaged illusion — that judgment has to come from people who actually possess the 20%. Putting it on arXiv was a choice not to dodge that evaluation.
Writing a paper
Building a framework and writing a paper about it are entirely different challenges. But the paper wasn’t just about announcing results. It was about forcing myself to organize what I’d built into the most rigorous format possible, put it in front of experts, and ask: “Is this actually meaningful?”
The world of research has an unspoken grammar. How to frame motivation, what an experimental design needs to demonstrate, what tone to use when reporting results. No amount of code will teach you these things. I’d never learned this grammar.
And yet, AI compressed this process too.
The related work survey is a good example. Mapping literature is one of the slowest parts of academic research. I described the project to AI and asked for adjacent work. It quickly surfaced papers across declarative runtimes, agent architectures, and world-model planning, and helped me see where my work sat in that lineage. A search that could have taken months compressed into a day.
The same went for the nuances of academic English. The subtle difference between “We propose” and “We introduce.” How to report results without overclaiming while still conveying significance. How to honestly acknowledge limitations without undermining contributions. AI corrected all of this in real time.
The paper I put on arXiv is titled “How Much LLM Does a Self-Revising Agent Actually Need?” What I wanted to ask wasn’t just whether the system worked. It was whether, once reasoning is externalized into an inspectable runtime, we can separately measure the moments where an LLM is actually needed and the moments where rule-based reasoning does better. I ran a staged decomposition of agent capabilities on top of the declarative runtime.
The initial results were interesting. Across 54 games (18 boards × 3 seeds) on a noisy Collaborative Battleship benchmark, adding explicit world-model planning alone raised win rate by 24.1 percentage points. LLM-based revision appeared on only about 4.3% of turns and actually reduced win rate. The point wasn’t leaderboard performance. It was showing that once reflection is externalized into a declarative runtime, you can empirically decompose where LLMs help and where they don’t.
I don’t know if this paper will be accepted. But at least I got to ask the question I wanted to ask. That alone puts me somewhere I couldn’t have imagined four months ago.
The day I put the preprint on arXiv, elation and anxiety hit simultaneously. arXiv isn’t a gatekeeping checkpoint — it’s a starting line. Whether my paper is a meaningful contribution, or whether blind spots I can’t see are fatal — that’s for the people who have the 20% to decide. I won’t dodge that judgment. The whole point of writing the paper was to invite it.
Where is the superintelligence?
The title of this essay is deliberately provocative. To be honest, I’m not even sure “superintelligence” exists yet.
But the tool in my hands opened doors to fields I thought I’d never reach. Not just one field — several at once. Before, there was a boundary: “I’m a frontend developer.” AI didn’t tear down that boundary. It gave me just enough gear to explore what’s on the other side.
These experiences are awe-inspiring. And honestly, frightening.
The awe is obvious. The range of intellectual territory a single person can access has expanded in an unprecedented way. The fear is equally obvious. When the feeling of “almost there” comes too easily, it’s easy to forget how much the remaining gap matters. And when things built without real understanding of that gap go out into the world, we risk a future where convincing illusions replace real expertise.
I don’t want that world. But I also don’t want to give up the possibilities AI has unlocked. Holding the tension between those two — I think that’s the task facing everyone who uses AI right now.
Epilogue: Screen off
I ran again this morning. During the run, I composed this essay in my head. Before handing the draft to AI, I worked out what I wanted to say.
The unnamed feeling from years of building SaaS — that intuition about an invisible structure shared across domains. No prompt could have generated that. AI merely translated that intuition into formalism.
But one question wouldn’t leave me the entire run.
The spot I feel I’ve reached in four months with AI — there’s an expert who spent ten years standing there. Right now, that expert is holding the same AI in their hands. Where are they going?
I thought AI helped me cross a boundary. But maybe the boundary didn’t break — it expanded for everyone simultaneously. While I was stepping into expert territory, the people already inside may be pushing far beyond what was possible before.
When that thought hit me, I turned off the screen and ran faster.